Probe Exraction
Concept
Probes from datasources come in different shapes and formats depending on the datasource’s technology, the query language and the driver-technology used.
For example: the result of an MDX-query on an OLAP-cube contains meta-data, that are not to be used within the testcase. Or a REST-API call returns an object-graph in a deep JSON-structure.
These heterogeneous data formats cannot be used directly for data-comparisons between each other, or for other inter-dataset operations. That’s why BiG EVAL’s validation-engine abstracts data from different technologies to make them uniform. We call that “Data-Extraction”.
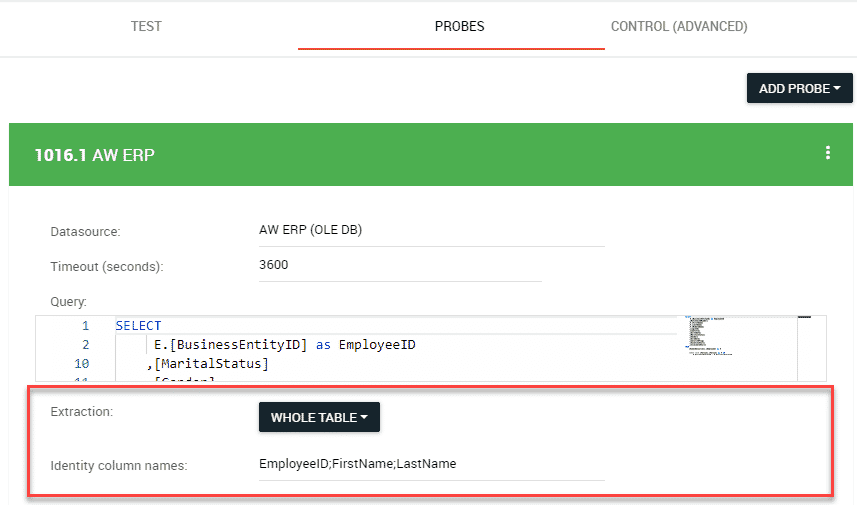
To tell BiG EVAL, which part of the probes data should be used in your validation-algorithm (testmethod), you need to tell BiG EVAL the Extraction-Settings you want to apply. You find these settings in the testcase-editor within each probe-definition.
Extraction Methods
There are several kind of extraction methods that can be applied onto the data queried from datasources.
Extraction of single values (scalar values)
Use one of the following extraction methods to get single values (a.k.a. scalar values) like KPI-Values, Function-Results (Sums, Counts etc.) as a probe value.
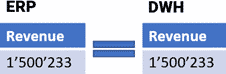
The following example of a testcase show the usage scenario of scalar values. There is a scalar value probe from the ERP that returns the actual revenue. And there is another probe, that queries the same from the data warehouse. The validation-algorithm compares these two values.
Value of the first cell
This extraction-method can be used to get a scalar value out of any shape of query-result.
If there’s a full table of data with multiple cells, it extracts only the first cells value. It extracts the value from the first row and the firs column.

And if there’s only a single cell returned by the query, it does the same: extracting the first and only cell.

Value of a specific cell
Use this extraction-method to extract a specific cell (not specifically the first one) from a dataset. So it extracts a specific column from the first row.
Which row it should use, can be defined either by the name of the column, or by the zero-based position of the column (in the following example it would be the position 1 or column-name ‘Year’).

Extraction of multiple values
If you intend to use multiple values as probe-values, you can use one of the following extraction-methods to shape your data. This allows to use one single datasource-query to fetch multiple KPI-values (or similar) in a single probe and single query. This makes the testcase even more efficient.

The following example shows how multiple values can be used in a specific testcase. This scenario queries the revenue and the costs of goods (COGS) from the ERP and compares them against the same KPI’s from the data warehouse.

Values of multiple cells
This extraction-method takes the values of multiple cells from the first row of the queries result. The result (the probe) is a table with one single row but multiple columns.
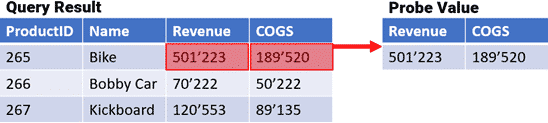
Define the columns to be extracted by either telling BiG EVAL the names of the columns or the zero-based position of the columns within the query-result. Multiple columns-names or -positions can be defined by separating them with a semicolon.
Revenue;COGS
Values of the first row
This extraction-method takes all columns from the first row of the queries result.

Tabellaric Extraction
If you intend to use a full table with multiple rows and columns as the probe-value, you can use one of the following extraction-methods. Tabellaric probes can be used to implement table-comparisons, matrix-comparisons, grouped KPI’s and many more.
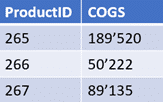
The following example shows a comparison of grouped sums of COGS. One grouped table comes from the ERP, and the other one from the data warehouse. Differences would be detected by BiG EVAL and can be seen in the testresult.
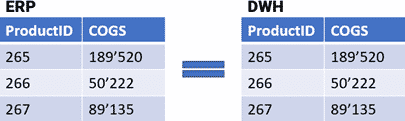
Values of multiple columns
This extraction method extracts the values of multiple specific columns of a query-result. The probe-value will then be a table with multiple columns and multiple rows.
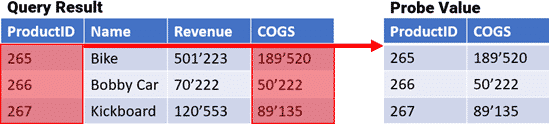
Define the columns to be extracted by either telling BiG EVAL the names of the columns or the zero-based position of the columns within the query-result. Multiple columns-names or -positions can be defined by separating them with a semicolon.
ProductID;COGS
To identify each row, you need to define one or multiple columns as the primary key of the probe. You do this the same way like defining the columns to extract.
ProductID
Whole Table
Use this extraction-method to use the whole datasource-query-result as your probe. So there will not be any reshaping of the queries result.

To identify each row, you need to define one or multiple columns as the primary key of the probe. If you do not define the primary key columns, a row-by-row comparision will be done. Use either the column-name or the zero-based position. Combine multiple columns by separating their name or position with a semicolon.
ProductID