How to Create a DataOps Process for Data Testing with Data Quality Software
In this article, we're going to take a look at the world of DataOps and explore an increasingly common challenge: how to harness data quality software to automate data quality and testing in complex data warehouse environments.
At BiG EVAL, we've seen increased demand for data quality and data testing use cases within DataOps environments.
As business intelligence architect and operations teams grapple with the complexity of managing multiple analytics environments, it has become an urgent priority to devise more innovative ways to deliver large-scale, automated data testing.
What is DataOps?
Before we discuss DataOps data testing, we need to provide a brief overview of DataOps.
DataOps is a relatively young discipline that has gained traction as companies recognize the need for more effective ways to manage data landscape complexity, particularly with business intelligence and data analytics.
Data warehousing has become a valuable deployment use case for DataOps due to the enormous volumes of data and the number of inbound/outbound pipelines operational teams need to control when delivering a data analytics capability.
DataOps aims to simplify the organization and orchestration of core data functions in much the same way that DevOps did for controlling software.
The DevOps fundamentals of agile, lean, and continuous delivery still apply to DataOps, but applying agile approaches to data increases the difficulty to a whole new level.
(Note: We provide links to useful articles/research on DataOps at the end of this article).
Why Has DataOps Testing Become a Problem for Data Warehousing and Analytics?
Even a modest data warehouse operation still needs to coordinate thousands of changes every year to ensure business users have access to accurate and timely information.
To maintain trust in the data, data analytics operations teams need to ensure all changes get thoroughly tested across all environments (e.g., dev, QA, pre-production, and production).
This requirement for data testing presents a challenge because:
The Data Quality Dimension
A further challenge is that DataOps data testing doesn't just require a processing change to trigger a round of testing.
The DataOps team needs to ensure that any data flowing through the pipelines and systems of a data analytics environment are continuously monitored and assessed against a comprehensive library of data quality rules.
DataOps Presents a Different Level of Complexity Compared to DevOps
The added complexity of data is what makes DataOps intrinsically more complex than DevOps:
Building Data Warehouse Testing for DataOps Deployment with Data Quality Software
This next section of the article will discuss some of the most recent data warehousing use cases we've been involved with, highlighting the benefit of integrating a data testing capability within a DataOps environment.
What Do You Need from a DataOps Data Testing Solution?
When we talk with clients, here are some of the typical challenges they're looking to solve:
Closing the Gap Between Business Needs and DataOps Delivery
Most data teams have a perennial challenge of keeping up with the business demand for analytics.
Unfortunately, most companies rely on outdated data testing practices. With the volume and frequency of data tests required in a busy data analytics environment, it's easy for cracks to appear.
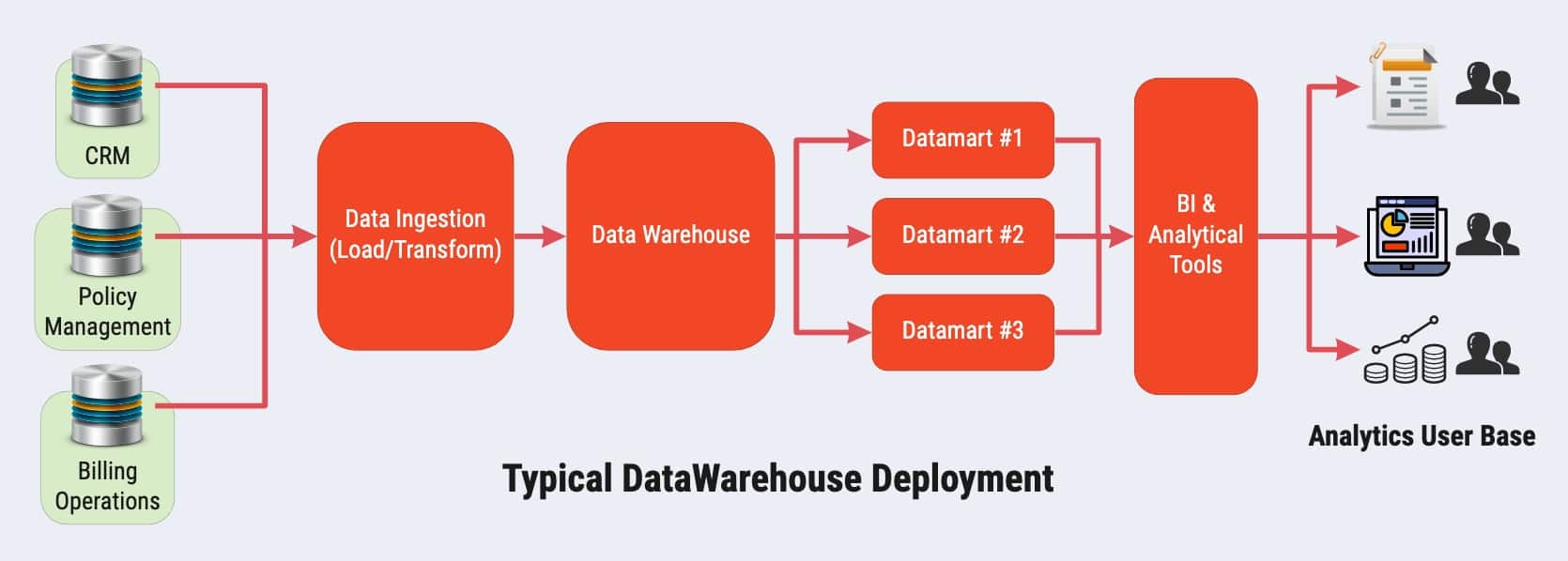
The diagram below highlights a simplified data warehouse environment found in many data analytics operations:

As you can see, this is a standard data warehouse configuration that requires extensive data testing at various locations.
Let's walk through each testing stage and explain how to approach it for optimal success.
Source and Target System Data Quality Assurance
You've probably heard the phrase, "Garbage in, garbage out."
It's a sad reality that many data warehouse environments ignore the most critical data test of all: monitoring the quality of inbound and outbound data flowing from production systems into the analytics platform and onward to further operational, analytical, or reporting systems.
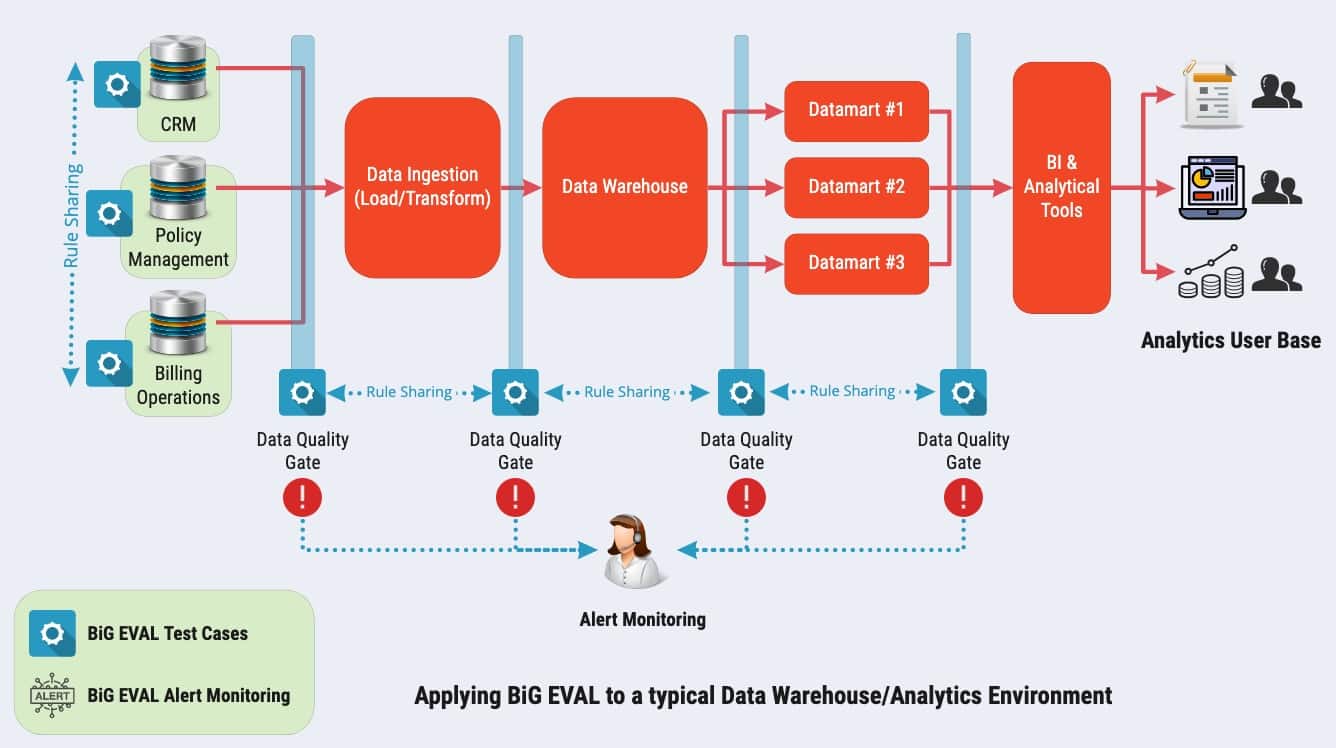
To address this, you need to deploy a data quality management testing/monitoring capability at the point of data ingestion before the data enters your warehouse.
As you see in the diagram below, we deploy our BiG EVAL Data Quality Management tool within the client analytics environment to perform this function:

There are some profound benefits from deploying a tool such as BiG EVAL Data Quality Management in this context:

Data Test Automation
Data Warehouse environments are continually evolving and updating, hence the need for a DataOps capability to serve the insatiable analytics appetites of the modern enterprise.
Your data testing solution needs to fit into this paradigm.
With DataOps, each time a developer makes a feature change, they need to execute an associated set of data tests to confirm they won't break anything when that feature is promoted to the production environment.
With each added feature, the number of tests increases exponentially because even a simple piece of code or logic can require a large number of data tests. The testing team soon becomes a bottleneck due to test saturation if forced to test scripts and routines manually.
This ability to align your data testing requirements to the scale and volume required for DataOps is one of the increasingly common use cases we see right now for data test automation.
When you synchronize data testing with continuous development and integration, you also ensure that any feature releases are gated (as with the data quality gates mentioned earlier). Changes can't pass into production without the required data tests being executed and successfully achieving their predefined thresholds.
In the old world of manual data testing, it was common to release features without appropriate testing simply because the testing resource was limited and the timescales required were impractical.
With the automated data testing approach we provide with BiG EVAL, everything changes. You can harmonize data testing with each sprint and feature drop coming out of your DataOps process.
Let's explore how we can approach this.

With Which DataOps Foundations Does Your Testing Approach Need to Align?
Continuous Integration and Deployment
Operating within a continuous delivery pattern requires development teams to work with a trusted source of testing rules, just as they work with a single code source in the DevOps world.
With BiG EVAL, we've made it our mission to eliminate the traditional approach of scattered data testing rules. Our solution is built around a managed repository of data testing rules shared among your operational environments while retaining a single source of truth.
Data Pipeline Orchestration
Orchestration is delivered through various operational workflows that call and coordinate the many data pipeline functions required to successfully move data around the analytics environment or other data processing stages.
As such, you could argue that orchestration provides the "engine room" of your DataOps capability.
Your data quality and data testing routines need to be called from the orchestration workflows.
DataOps Requires Test Automation
You can't deliver DataOps with manual testing, hence the need for automated testing.
Executing automated tests under a DataOps environment means that test scripts and specifications must be created in advance with every new analytics feature or update.
With test automation, it's much easier to run your tests regularly and often. You're also not just testing code but the data itself.
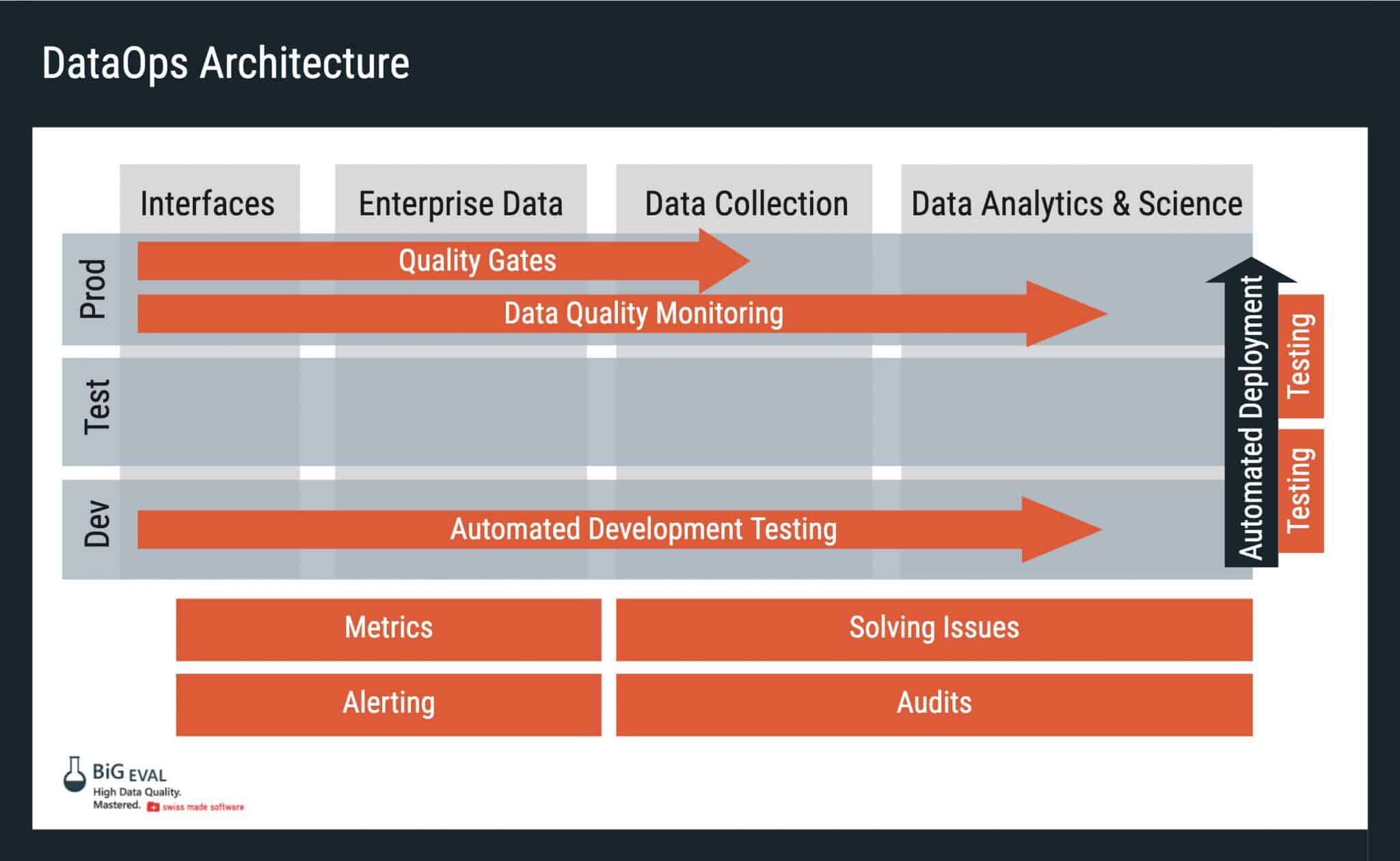
The image below provides a quick overview of where BiG EVAL Data Test Automation is deployed, giving you a sense of the breadth of testing scenarios you need to support in a DataOps environment:

Monitoring
With the focus on the increased deployment speed that DataOps must support, there is an added need to monitor the entire data analytics environment to ensure any defects and anomalies are trapped before they cause serious harm.
Monitoring and testing need to work in tandem. Once issues are detected, new data testing rules can be created to ensure future defects are trapped within the source data environment, and any code releases don't create defects.
Putting It All Together
The following diagram highlights where data test automation and quality testing need to be executed to support DataOps in a standard data warehousing configuration.

Of course, we're biased at BiG EVAL in that our testing solutions operate exceptionally well in this configuration.
Still, whatever testing solution you opt for, you'll find that for your DataOps environment to function, you'll need to deploy this type of arrangement.
Resources and Next Steps
If you want to learn more about automating data tests and data quality within a DataOps environment, the following resources may be helpful:
FREE eBook

Successfully Implementing
Data Quality Improvements
This free eBook unveils one of the most important secrets of successful data quality improvement projects.
Do the first step! Get in touch with BiG EVAL...