Automated DATA Testing
Data Product Testing Bottlenecks:
How to Achieve Massive Scaling the Easy Way
Discover how to streamline data product testing, achieve comprehensive coverage, and improve quality assurance through the power of massive scaling.
Author: Thomas Bolt
Date: May 2024
Testing can take up a lot of time in IT projects when architects and developers could be working on valuable new functions. At least that's what many people think when it comes to setting up a new project. And all too often, this leads to quality assurance being neglected and having to take a back seat to budget and time planning. In this article, we show that this does not have to be the case, especially in data product projects, and that quality assurance can be implemented simply, efficiently and in a highly scalable manner.
The Testing Bottleneck in Agile Data Product Projects
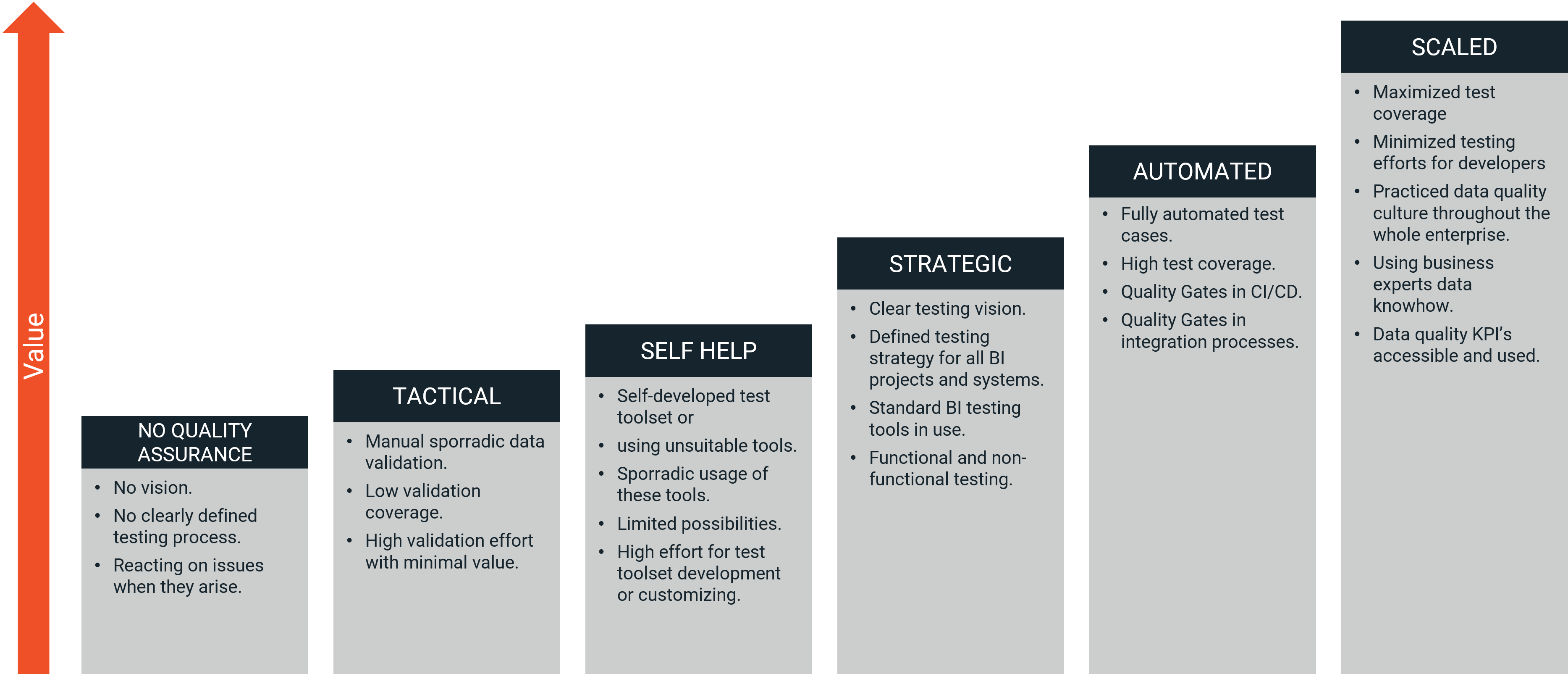
Current Testing Practices: A Maturity Model Perspective
Based on many customer contacts and assessments, we have created a maturity model for testing in data product projects. It is used to evaluate and improve test procedures that teams utilize to assure the quality of what they are building. Most projects find themselves somewhere within the first three levels.
- Level 1: No testing - This level represents a complete lack of testing, where teams rely solely on developer testing and user feedback. High defect rates, long debugging times and poor product quality not only leads to dissatisfied users but also to expensive issues in the whole organization.
- Level 2: Tactical testing (also known as "firefighting") - This level involves ad-hoc, manual testing, often performed in a reactive manner to address immediate issues. Resources are used inefficiently and fixing issues immediately and in between other tasks developers are working on is stressful and leads to resignation.
- Level 3: Self-help solutions - At this level, teams invest significant time and resources into building their own testing frameworks instead of investing forces into the data product development. This approach often results in high maintenance costs, bounded resources and limited scalability.

The Limitations of Manual Testing in Agile Projects
Manual testing is possible in the early stages of an agile project, but it quickly becomes unsustainable. As the project progresses, the testing effort accumulates, because not only new features of the data product need to be tested. All features that were built in the sprints before need to be tested again to assure they still work. This so-called regression testing is essential because side-effects of development work could lead to completely unexpected defects and behaviors of existing functionality.
Running all these test cases manually soon becomes too time-consuming to be fulfilled during a short sprint. This situation usually leads to:
- Testing becomes a significant bottleneck in the development process.
- Teams are struggling to meet release deadlines.
- Features being released with defects or issues because time-consuming test cases get dropped.
- Users experiencing poor product quality.
- Costs explode because more testing resources are added to the project.
Why Automation is Essential
To ensure thorough and efficient testing in agile data projects, automated testing is essential. Especially as the product scales and complexity increases. By automating testing, teams can build test cases once and run them as many times as needed fully automated. This shifts a lot of effort from repetitive manual testing to test case development which needs muss less work.
What about data warehouse automation solutions?
To maintain the pace of agile development, teams utilize software to automatically generate components of their data products. Data warehouse automation solutions like WhereScape, AnalyticsCreator or DataVault Builder bring massive traction to a project, but do not prevent the data product from being carefully tested. Because the project progresses faster with such solutions and more functionalities can be developed within a sprint, more test cases are also required. However, as we will see later in the article, standardization and descriptive metadata bring us great advantages in the automation of test processes.
Massively Scaling Testing
What is Massive Scaling?
Massive scaling in data product testing is a revolutionary approach that enables teams to test a vast number of entities with a minimum of testing time and effort. Teams efficiently ensure comprehensive testing coverage without the burden of creating and maintaining hundreds of test cases. In this concept, one test case that validates a specific behavior or functionality of a system, gets automatically applied to hundreds or even thousands of entities or system components that exhibit the same behavior or functionality. This is made possible with test automation software specialized for data products.
Assuming there is a test case that checks whether the historization of a data warehouse dimension works correctly. In most data warehouses, there are dozens of dimensions that historicize data. This is where massive scaling comes into play, as this single test case is automatically executed for all other historicized dimensions. The advantages are obvious.
Success Story: 17’000 Test Executions from Just a Handful of Test Cases
Helsana, a leading Swiss health insurer, achieved a remarkable milestone on the road to data validation and test automation with BiG EVAL. By implementing a handful of test cases only that leverage BiG EVAL’s massive scaling capabilities, an astonishing 17,000 test executions were performed daily!
This groundbreaking test coverage and clarity on data quality enabled Helsana to gain a comprehensive view of the health of their data and fix issues at an unprecedented pace. Helsana transformed their manual testing process into a streamlined, efficient, and highly effective system, setting a new standard for data validation and test automation in the industry.
17'000 Test Cases a day!
Massively Scaled Test Coverage
Why Massive Scaling is Possible in Data Product Projects?
Data products consist of several types of components like data integration pipelines (ETL/ELT), archive tables, dimensions, fact-tables and much more. Each component type is implemented multiple times using the same architectural and implementation principles because they are doing the same thing, but just for different entities. For example, the dimension table for customer data and the one for product data usually share a common architecture. The main difference is just the specific data model being stored or processed.
This commonality in architecture which is present especially in data products like data warehouses, enables massive scaling, as test cases can be applied across multiple components of the same type with only minimal modifications like different business keys, attribute names or similar. And even these modifications can be automated by tools like BiG EVAL. More about massive scaling with BiG EVAL
So, there are the following main ingredients for massive scaling:
- Architectural Similarity
- Meta data
- Automation
Controlling Test Cases with Meta Information
Massive scaling heavily depends on information about entities like table-names, column-descriptions, data types and foreign-key-relationships. This information allows a test automation solution to discover the data landscape to find similar components like, for example, data warehouse dimensions where a specific test case can be executed against. But meta data also allows the test automation solution to adjust test cases to specific naming, attributes, or other behaviors of such a component or data model. The test automation solution automatically sets up database queries needed and adjusts test algorithms, test result representations and even alerting processes.
Fortunately, data structures are usually well described in the form of meta information (or metadata). You probably think that this does not apply in your specific case because you do not have complete documentation yet. But I can reassure you. Almost every data management technology provides the required information in a schema catalog. Based on this, your massive scaling can be implemented very well.
If you operate a data catalog solution such as Collibra or a data warehouse automation solution such as AnalyticsCreator, DataVault Builder or WhereScape, these solutions even provide information on data lineage. Say, they provide information about where data comes from, how it gets transformed or combined and where it gets stored. This allows you to implement fully automated and scaled end-to-end testing that validates all architecture levels of your data product.

Automating Test Cases
In massive scaling test scenarios, there’s no way around automation. The massive scaling pioneer BiG EVAL for example, comes with the concept of test case instances. It means that the solution discovers the data landscape each time massive scaling test cases get started. It immediately produces a test case instance for each entity it runs against (e.g. customer, product, sales order). This allows the test automation solution to dynamically adapt to the current data landscape or project implementation progress. So, if developers add new dimensions to the data warehouse, they don’t even need to think about testing, because these dimensions get automatically integrated into the testing process and test coverage is maintained.
Benefits of Massively Scaled Testing
Improved Efficiency and Productivity
Massive scaling brings a significant boost to efficiency and productivity in data product testing. By automatically scaling out test cases across multiple components and entities, teams can achieve comprehensive test coverage in a fraction of the time it would take with traditional testing methods. This means that testing efforts get shifted from test execution to test development which is more calculatable and needs less time. Freeing up valuable resources and enabling teams to focus on other critical tasks enables teams to achieve more with less, streamlining their testing process and accelerating their data product development pipeline.
Enhanced Test Coverage and Accuracy
Massive scaling enables the application of test cases according to the "watering can principle", where a single test case is applied broadly across various components, entities, and scenarios, providing comprehensive test coverage and identifying potential issues. It enables extensive testing of multiple implementations of the same architectural component, ensuring that they work error-free and consistently, significantly enhancing test efficiency and effectiveness, and allowing teams to validate the reliability and accuracy of their data product components at scale.
Reduced Maintenance and Support
Massive scaling significantly reduces maintenance and support efforts by allowing a single test case to be applied to hundreds or thousands of entities, eliminating the need to multiply test cases. Unlike traditional test solutions, where multiple test cases of the same type need to be maintained, massive scaling enables teams to maintain just one test case, reducing the overhead of test case management and updates. This results in a substantial decrease in maintenance and support costs, freeing up resources to focus on more strategic initiatives and ensuring that testing efforts remain efficient and effective.
>> How to Get Budget and Executive Buy-In to Improve Data Quality <<
Taking away Testing from Developers
Developers often view testing as a tedious and time-consuming task, and with massive scaling, they can now devote their time and energy to writing code and building new features. The automated application of test cases to new entities ensures that testing is done comprehensively and efficiently, without requiring manual intervention or developer involvement. This not only boosts developer productivity but also leads to higher job satisfaction, as they can concentrate on the creative aspects of software development, while testing is taken care of seamlessly in the background.
Conclusion
In conclusion, massive scaling in test automation is a revolutionary approach that transforms the testing process for data product projects. By leveraging architectural similarity, metadata, and automation, teams can achieve comprehensive test coverage with minimal effort and resources. The benefits of massive scaling are clear: improved efficiency and productivity, enhanced test coverage and accuracy, reduced maintenance and support, and increased developer productivity and job satisfaction. By adopting massive scaling, teams can streamline their testing process, accelerate their development pipeline, and ensure the quality and reliability of their data products. Embrace the power of massive scaling and take your testing to the next level!